
Running our own Ethereum node
It can feel overwhelming to of running our own node, where do we even start?
I started with the official documentation and it took me quite a bit of reading to get a good grasp of the situation. I decided to take notes in case they are helpful for other folks wanted to break into the field.
The first question I had to ask myself is do I really want to install a full node? would a different solution be enough.
The main objective for me installing a node is to learn more about the technology so doing everything from scratch seems like a good way to do so. In addition to learning about it, another objective I have is to be able to do data analysis with all the information publicly available on the blockchain. It seems ideal to be able to download a full history of transactions and play with them.
Options
There are other ways to get access to the blockchain besides running your own node. If the amount of data you want to process is small or you have a very well defined use case you want to try I probably wouldn’t recommend running your own node. To make development faster I would use one of the companies specializing in blockchain infrastructure or I would run a managed node on the cloud. I don’t have much experience with them so I won’t live a list pros and cons. I will only mention a few: alchemy, infura, quicknode and blockdaemon. Note that at the time of the writing, alchemy is valued at 10B and aims to become the aws of blockchain. These aren’t really small companies anymore.
Coming back to our humble objective: run an Ethereum node and do some interesting data analysis.
I learned there are three different types of nodes you can run:
- Light: this node downloads only block headers with a summary of the contents in a block. It can’t participate in consensus and still needs to connect to a full node to get its information. This option doesn’t look very interesting.
- Full: this is closer to what we were looking for. It participates in block validation, provides data on request and stores blockchain data. The caveat with this type of node is that it doesn’t store a full record of transactions, it only stores the most recent 128 blocks. We could get started with this one but the data analysis would be limited to only the last 128 blocks plus if those blocks keep changing our results won’t be easily reproducible.
- Archive: a full node with the complete history of the blockchain. This is exactly what we were looking for! The complete set of transactions in Ethereum since the very beginning.
Blockchain clients
Now we know we want our own Ethereum Archive. I don’t know yet how we will extract or process the data but we will cross that bridge when we get there. For the moment, let’s download our archive!
Here we get to our next decision, which client do we use? it turns out there are several of them.
Erigon seems to do a really good use of space and can store the whole archive in +2TB while GETH needs +10TB.
I decided to go with Erigon and will install that one.
A small complication here is that my laptop doesn’t have enough space to store the extra terabytes needed. I did some research and found a really nice portable drive on amazon: sandisk extreme portable ssd 4TB. It’s the biggest external hard drive I have found so far (4TB) and I am extremely impressed by its physical size. It’s tiny! I didn’t pay attention when I ordered it and was so surprised when I received it. It’s about 10cm long and 1cm thick.
Execution Layer (Erigon)
Now that we have chosen a client and have a place to put all the data let’s give it a try!
A good place to start is the readme of the project Erigon.
Walkthroughs found online:
- Getting Started with Erigon on Ubuntu
- Setting up a Full Erigon Ethereum Node
- Running an Erigon Archive Node
Installing Erigon
Things you need:
- git
- Xcode Command Line Tools installed
- Go
Install Xcode Command Line Tools with Homebrew
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
git clone --recurse-submodules -j8 https://github.com/ledgerwatch/erigon.git
cd erigon
make erigon
./build/bin/erigon --datadir mainnet
INFO[09-21|16:49:03.690] Build info git_branch=HEAD git_tag=v2022.09.01-dirty git_commit=4067b7c4da6c5d741d3027d95ae2afdf6b7a943a
INFO[09-21|16:49:03.691] Starting Erigon on Ethereum mainnet...
INFO[09-21|16:49:03.694] Maximum peer count ETH=100 total=100
INFO[09-21|16:49:03.694] starting HTTP APIs APIs=eth,erigon,engine
INFO[09-21|16:49:03.694] torrent verbosity level=WRN
INFO[09-21|16:49:05.796] Set global gas cap cap=50000000
INFO[09-21|16:49:05.884] Opening Database
Here we buckle up! it took quite a while to download 220GB. Unfortunately, the process wasn’t completely smooth and there were some errors
EROR[09-21|06:04:08.060] Staged Sync err="[1/15 Headers] BuildMissedIndices: TransactionsIdx: at=7000000-7500000, runtime error: slice bounds out of range [:-1], [block_snapshots.go:1537 panic.go:890 panic.go:139 decompress.go:523 block_snapshots.go:1518 block_snapshots.go:1541 block_snapshots.go:760 block_snapshots.go:801 asm_arm64.s:1165]"
INFO[09-21|06:04:08.561] [Snapshots] Fetching torrent files metadata
INFO[09-21|06:04:08.971] [Snapshots] Stat blocks=6500k indices=6500k alloc=5.9GB sys=9.0GB
EROR[09-21|06:04:09.010] Staged Sync err="[1/15 Headers] BuildMissedIndices: TransactionsIdx: at=7000000-7500000, runtime error: slice bounds out of range [:-1], [block_snapshots.go:1537 panic.go:890 panic.go:139 decompress.go:523 block_snapshots.go:1518 block_snapshots.go:1541 block_snapshots.go:760 block_snapshots.go:801 asm_arm64.s:1165]"
I asked in the Erigon discord and learned a couple of new commands:
make downloader
./build/bin/downloader torrent_hashes --verify --datadir=mainnet
Which verifies the download and gave me more details of the errors and another command to run the download with it in place
./build/bin/erigon --downloader.verify --datadir mainnet
Weirdly, that one ran for a few hours and gave me another strange error but I ran it again and it managed to finish this time 🥳
Consensus Layer (Teku)
I thought that would be enough to get the client running but I also learned things have changed with the Merge and I now needed a Consensus Layer. I didn’t know what that was so I asked for pointers and Alex from Erigon shared the following links:
https://ethereum.org/en/upgrades/get-involved/#clients https://ethereum.org/en/developers/docs/nodes-and-clients/#consensus-clients https://ethereum.org/en/developers/docs/nodes-and-clients/client-diversity/#consensus-clients
The gist of it is that a “full node requires running a pair of these clients: an execution layer client and a consensus layer client”.
I found this article very helpful: Execution Layer (EL) and Consensus Layer (CL) Node Clients (2022)
The short story here is that the old self-contained Erigon client has now become the execution layer and in addition to it we now need to install a second client to run the consensus layer.
Installing Teku
In the previous section we installed Erigon, which runs the execution layer. Now we will complement this with a second client running the consensus layer.
There are several options at the moment.
I decided to give Teku a try because is written in Java (a language I speak), it’s open source and it’s developed by ConsenSys.
brew tap ConsenSys/teku
brew install ConsenSys/teku/teku
Command to start Start teku:
teku \
--ee-endpoint=http://localhost:8551 \
--ee-jwt-secret-file=/Users/leodonethat/eth/erigon/mainnet/jwt.hex \
--metrics-enabled=true \
--rest-api-enabled=true \
--data-base-path=/Users/leodonethat/eth/teku/ \
--data-storage-mode=archive \
--network=mainnet
We realize we don’t have a file jwtsecret.hex yet.
It turns out Erigon automatically creates one with name jwt.hex in the datadir directory so we will try using that one. Let’s try launching Erigon and then Teku
/Users/leodonethat/eth/build/bin/erigon --datadir mainnet --http.api=eth,erigon,web3,net,debug,trace,txpool
Note: Erigon has a number of APIs available, we have to make sure to include the one we need when launching it or we will get an error “the method does not exist/is not available” when making calls from different APIs.
teku \
--ee-endpoint=http://localhost:8551 \
--ee-jwt-secret-file=/Users/leodonethat/eth/erigon/mainnet/jwt.hex \
--metrics-enabled=true \
--rest-api-enabled=true \
--data-base-path=/Users/leodonethat/eth/teku/ \
--data-storage-mode=archive \
--network=mainnet
Syncing
At this point we have our Ethereum node up and running 🥳. The next step is waiting for it to sync. Be ready for it to take a veeeeeeeery long time. We are talking about days if you have a solid internet connection.
We can use the eth_syncing command to see how we are doing. Here we note that we are currently at node 0x0. This is definetly take a while.
% curl -H 'Content-Type: application/json' -X POST http://localhost:8545 -d '{"jsonrpc":"2.0","method":"eth_syncing","params":[],"id":51}'
{"jsonrpc":"2.0","id":51,"result":{"currentBlock":"0x0","highestBlock":"0xe5ab0f","stages":[{"stage_name":"Headers","block_number":"0xe5ab0f"},{"stage_name":"BlockHashes","block_number":"0xe4e1bf"},{"stage_name":"Bodies","block_number":"0xe4e1bf"},{"stage_name":"Senders","block_number":"0xe4e1bf"},{"stage_name":"Execution","block_number":"0x0"},{"stage_name":"Translation","block_number":"0x0"},{"stage_name":"HashState","block_number":"0x0"},{"stage_name":"IntermediateHashes","block_number":"0x0"},{"stage_name":"AccountHistoryIndex","block_number":"0x0"},{"stage_name":"StorageHistoryIndex","block_number":"0x0"},{"stage_name":"LogIndex","block_number":"0x0"},{"stage_name":"CallTraces","block_number":"0x0"},{"stage_name":"TxLookup","block_number":"0x0"},{"stage_name":"Finish","block_number":"0x0"}]}}
Be ready to wait for a loooooooog time during the first sync. I didn’t run it consistently so it’s hard to estimate but I would say at least a few weeks. Once you the syncing is done you should get the follwing answer from the command above.
{"jsonrpc":"2.0","id":1,"result":false}
Testing our node
Since my main objective of running a node is to do analytics. I do not need it to be syncing all the time. One option
is t use the option --sync.loop.throttle when launching erigon to specify the timing between syncs.
Another option is to run only the rpcdaemon.
$ cd eth/erigon
erigon$ make rpcdaemon
Building rpcdaemon
Run "eth/erigon/build/bin/rpcdaemon" to launch rpcdaemon.
./build/bin/rpcdaemon --datadir mainnet --http.api=eth,erigon,web3,net,debug,trace,txpool
One more trick (the one I ended up using) is that after the initial sync we can switch off the consensus layer (Teku) and leave only the execution layer (Erigon). Like that it can answer our requests but it will not be downloading more data.
I suggest reading more about the JSON-RPC interface to see what commands are available.
curl -H 'Content-Type: application/json' -X POST --data '{"jsonrpc":"2.0","method":"eth_getBalance","params":["0x3f5ce5fbfe3e9af3971dd833d26ba9b5c936f0be", "latest"],"id":1}' 127.0.0.1:8545
{"jsonrpc":"2.0","id":1,"result":"0x17a3ea3eb70b228"}
The answer 0x17a3ea3eb70b228is 106466414947250728 in decimal but we have to remember this is denominated in wei which is the smallest unit of measurement for ether (10^18 wei is one ether). Which means in ether we have 0.106466414947250728 and at today’s price of $1,259.75 it means this address has a total balance of $134.12and it’s something we can double check in etherscan
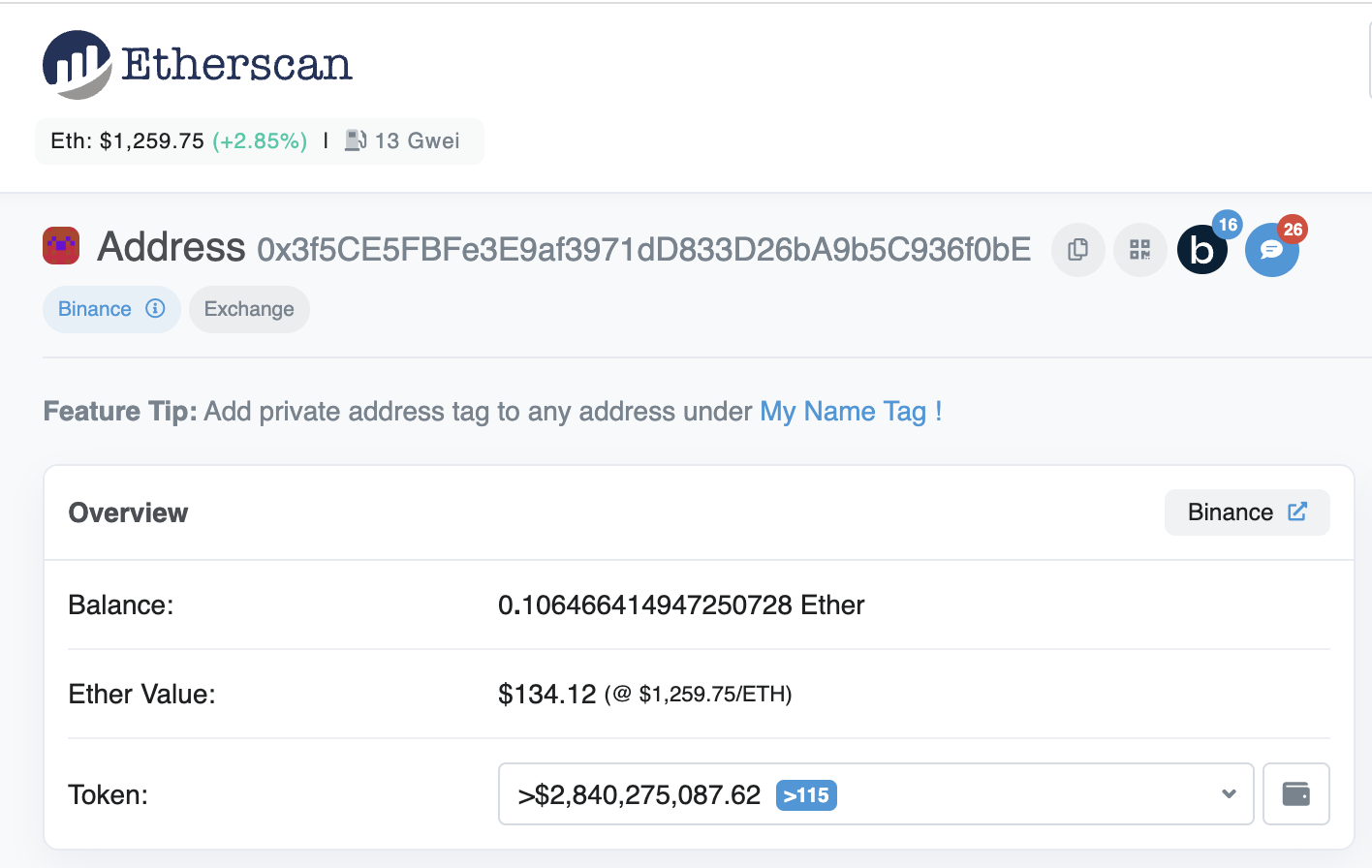
This is really really cool, we have or very own Ethereum portal!!
Acknowledgements
To be honest, this was a lot harder than expected. It took quite a bit of reading and trial and error. I can see why platforms like Infura and Alchemy have gotten so popular. The idea of spinning your own node within minutes is very very appealing.
Some resources were super helpful, for instance Magnus’ post:
There was also Thomas’:
Plus Thomas Jay is the developer behind TrueBlocks and he was super nice and friendly in their discord instance.
Another super help helpful person was Alex Sharov, developer of erigon, who was also super helpful on discord.