
The Modern Data Stack for Ethereum
I’ve been having a blast exploring some amazing places and indulging in my hobbies during my free time. Learning Swahili, practicing self-defense, and scuba diving have been some of the highlights of my adventures so far. But I wanted to take on a fun technical challenge as well, so I decided to build a blockchain analytics platform using modern open-source tools.
My goal was to create a proof of concept for an end-to-end data pipeline using The Modern Data Stack, an umbrella term for a set of data tools launched in recent years that enable us to implement a data pipeline. If you’re interested in learning more about it, you can check out this blog post by Fivetran or this one by dbt. There are many advantages to a more traditional approach, but what sets The Modern Data Stack apart for me is its modularity. Each step of the pipeline can be implemented by a different tool depending on our specific requirements, whether it’s open-source, on-premise, cloud-based, third-party, or in-house.
For this project, I focused on using open-source and user-friendly tools. In the past, it was difficult to find a combination of these two qualities, but I was pleasantly surprised to find that newer tools offer an excellent user experience. I suppose it doesn’t hurt that there are well-funded companies offering managed versions of their products!
The big picture
Without further ado, our Ethereum data stack:
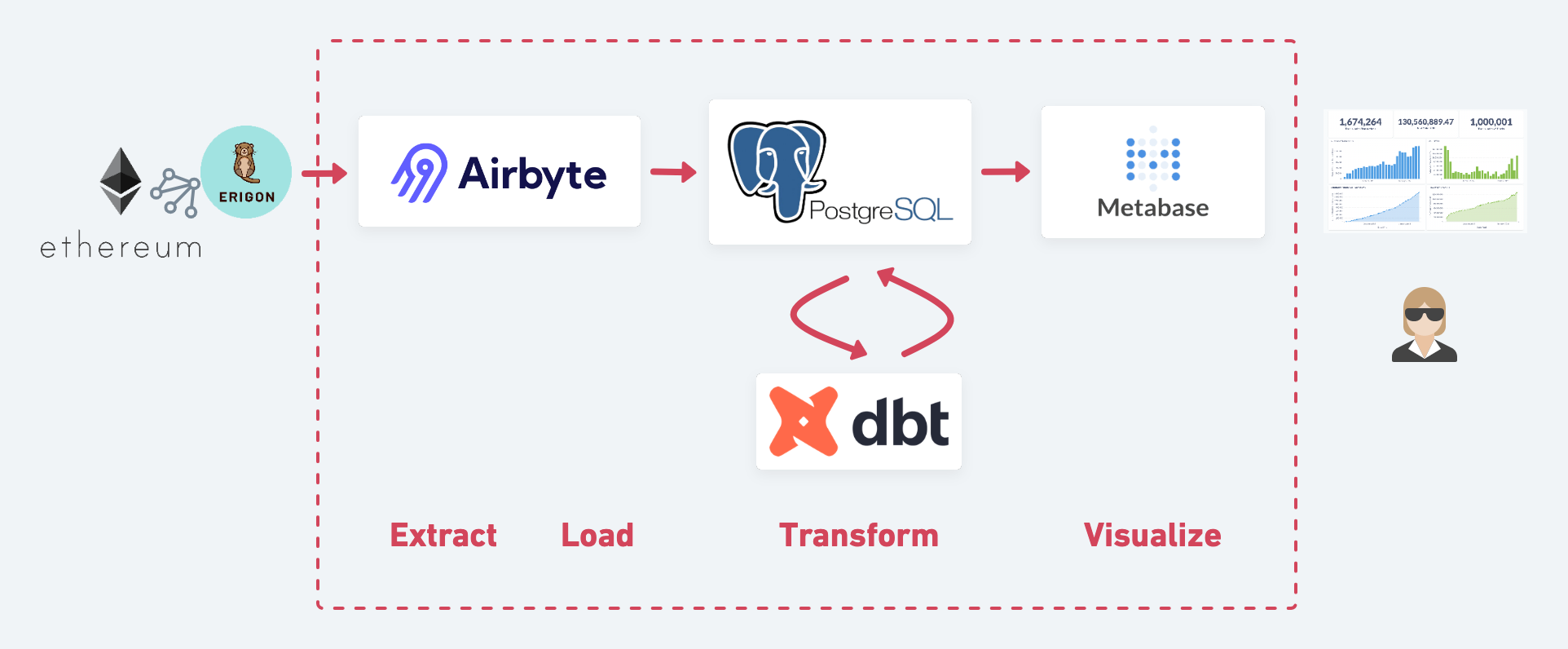
Following the data from left to right, we:
- Setup our own Ethereum node with Erigon to serve as the data source.
- Use Airbyte to extract the data from Erigon and load it into Postgres.
- Transform the raw data with dbt.
- Visualize our neatly transformed data with Metabase.
Lessons learned
- Setting up the Ethereum node proved to be the most difficult part of the project. I can see why node providers like Alchemy, Infura, and Quicknode are so popular! (and have seen their valuations skyrocket).
- The developer experience for Airbyte, dbt, and Metabase was nothing short of delightful. I am thrilled to see how much progress has been made in the past few years and are excited to see what the future holds.
Next steps
- Productionize our proof-of-concept code to ensure that all steps work efficiently when a new block is produced every twelve seconds.
- Add new data sources, such as downloading the price of ETH and tokens in dollars and other currencies.
- Deploy on the cloud and replace the local Postgres database with BigQuery or Snowflake to improve scalability (another big selling point of the modern data stack).
- Add an orchestration engine like Airflow or Dagster to handle an increasing number of tasks.
- Add a data catalog like DataHub to serve as a metadata management system and keep track of a growing number of data artifacts. While not open-source, a newer tool like metaphor has amazing features like column-level lineage and social annotations.
- Ensure data quality, with a tool like great expectations.
Competition
What would be the world without friendly competition?! If you can’t wait to learn more and are eager to dive in I have great news: there are folks out there working tirelessly to provide free blockchain data in a user-friendly format. I highly recommend checking out Dune Analytics and Flipside Crypto for a sql interface. If you’re looking for more curated tools that are perfect for specific use cases, you might want to explore Nansen, Glassnode, or Messari. These tools are all excellent resources for anyone looking to learn more about blockchain data.